Esercitazione 1
Per capire bene cos'è il Verilog è bene partire dal capire per cosa si usa. È un Hardware Description Language, cioè un linguaggio formalizzato per la progettazione e realizzazione di componenti hardware: da reti combinatorie a CPU, architetture avanzate e componenti dedicati a scopi specifici.
Lo scopo non è quindi solo descrivere dell'hardware con del codice anziché disegni, ma in generale supportare con strumenti utili l'ingegnere in tutte le fasi di progettazione di sistemi elettronici digitali, a partire dalla semplice prototizione dell'interfaccia (dove poco importa la realizzazione interna, ma solo l'algoritmo implementato), passando per la simulazione in testbench software, alla realizzazione fisica su FPGA e test in hardware.
Tutti questi scopi hanno richieste diverse, e semantiche relative diverse. Per questo non dovrebbe stupire il fatto che Verilog include molte diverse funzionalità e sintassi che hanno senso solo in specifici contesti e non altri, che spazia dalle porte logiche elementari a strutture di programmazione stile-C e funzionalità di stampa a terminale.
Questo è spesso fonte di confusione, visto che il compilatore Verilog non aiuta a fare queste distinzioni, anzi, supporta intenzionalmente diversi modi di usare le stesse keyword, come reg che può essere utilizzata sia come variabile di un programma che come un registro in una rete sincronizzata.
Come vedremo, è importante tenere presente cosa si sta facendo e perché per poter capire quale forma e sintassi ha senso usare e quale no.
Noi vedremo 3 usi diversi, in particolare:
- descrizione e sintesi di reti combinatorie
- descrizione e sintesi di reti sincronizzate
- verifica con testbench simulativa
Saper leggere o scrivere testbench non è parte degli argomenti d'esame. È tuttavia estremamente utile per esercitarsi provando con mano l'hardware descritto e capire come si comporta.
Per ogni esercizio, così come in sede d'esame, viene fornita una testbench adatta.
Da schemi circuitali a codice
La bussola fondamentale per scrivere Verilog è tenere sempre presente l'hardware che si vuole realizzare. Partiamo dall'idea di hardware che abbiamo tramite schemi, come nell'esempio in figura.
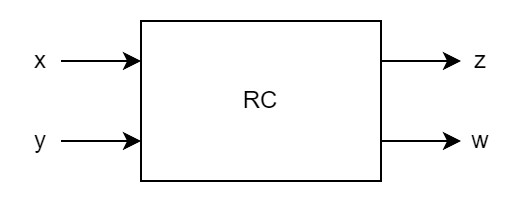
Questo schema mostra una generica rete combinatoria RC con ingressi x e y, e uscite z e w.
Questa rete logica sarà implementata poi con componenti elettronici.
Sappiamo che questi, in quanto componenti fisici reali, non hanno un concetto di ordine tra di loro, o sincronizzazione, o attesa: gli ingressi x e y variano indipendentemente, possono avere cambiamenti anche contemporanei e fluttuanti, e la rete RC risponde sempre a questi cambiamenti tramite le uscite z e w, anche durante i transitori dove gli ingressi variano da uno stato a un altro.
Questa può sembrare una ripetizione banale se si pensa ai segnali elettrici che si propagano in un circuito, ma è facile dimenticarsene quando si guarda al codice Verilog.
Vediamo come questo schema si può tradurre in codice.
module RC(x, y, z, w);
input x, y;
output z, w;
assign #1 z = x | y;
assign #2 w = x & y;
endmodule
In Verilog si dichiarano moduli in modo simile alle classi in linguaggi di programmazione: un modulo è un tipo di componente che altri moduli potranno poi usare.
La riga 1 inizia la dichiarazione del modulo, che è composta dal nome del modulo (RC) e dalla lista di porte di questo modulo, anch'esse con nome (x, y, z, w).
Queste porte possono essere di input e/o output, a uno o a più bit.
Specifichiamo questo alle righe 3 e 4. Mancando indicazioni di dimensione, saranno tutte da 1 bit.
Alle righe 6 e 7 specifichiamo il comportamento dei fili di uscita z e w.
Lo statement assign indica che l'elemento a sinistra assume continuamente il valore indicato dall'espressione a destra.
Con #1 si indica un fattore di ritardo nell'aggiornamento, di 1 unità di tempo.
Ogni rete combinatoria che non sia un semplice filo ha un certo tempo di attraversamento non trascurabile, ed è importante rappresentarlo con un elemento di ritardo.
Nel codice, vediamo che l'assign di z precede quello di w.
Questo però non ha nulla a che vedere con le proprietà temporali che li legano: con queste linee di codice rappresentiamo componenti hardware distinti che si evolvono continuamente, indipendentemente e contemporaneamente.
L'ordine degli statement di un module ha lo stesso valore dell'ordine con cui si disegnano le linee di uno schema circuitale: completamente irrilevante ai fini del risultato finale.
Questo rimarrà vero quando vedremo reti più complesse, dove dimenticarsi di questo porta a errori gravi.
Concetto di testbench
Abbiamo progettato il nostro hardware, la rete RC di cui sopra.
Vogliamo sapere però come si comporta, e in particolare se fa quello che ci aspettiamo dalle specifiche.
Per far questo, ho bisogno di mettere RC in un contesto in cui ne manipolo gli ingressi in un modo noto, così da conoscere quali output aspettarsi, e con della logica apposita misuro le uscite e verifico che corrispondano a quelle attese.
Tale ambiente è quello che chiamamo testbench.
Nell'esempio in figura, una rete checker controlla le uscite e con l'uscita ok indica se il test è andato a buon fine o no.
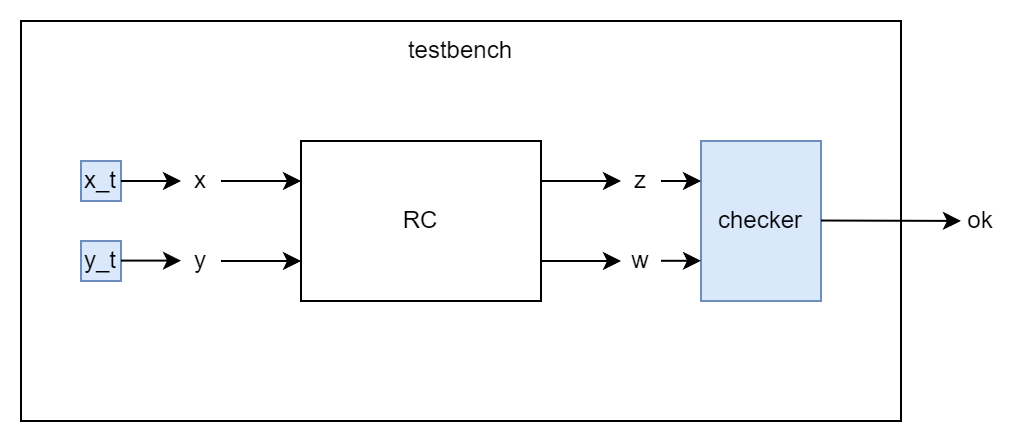
Il corrispettivo nel mondo software è un programma di test che prova i metodi e strutture dati di una libreria. Anche noto come unit test.
Una opzione è progettare questa testbench come un ulteriore componente hardware, e seguire tutti i passaggi necessari a realizzare con hardware vero la testbench con dentro la rete sopra descritta, per esempio con FPGA. Questo è sicuramente corretto, ma molto costoso, quantomeno nel tempo necessario a fare la verifica. Una opzione più interessante è usare la simulazione: si compila un programma eseguibile che simula il comportamento dell'hardware, almeno fino a un certo livello di dettaglio. Questo ci dà un responso in modo molto più efficiente, visto che si può modificare, ricompilare e rieseguire in pochi secondi vedendo il risultato direttamente a terminale.
Si può fare un passo in più: anziché progettare la testbench come dell'altro hardware con semplice uscita ok, si sfrutta appieno la natura software della simulazione per scrivere qualcosa che è più simile a un programma di test, dove abbiamo effettivamente ordine e temporizzazione tra gli statement, insieme ad altri concetti che sarebbero privi di senso al di fuori della simulazione.
Questo ci fornisce un modo per fare debugging su descrizioni di hardware.
module testbench();
reg x_t, y_t; // "variabili"
wire z_t, w_t;
RC rc (
.x(x_t), .y(y_t),
.z(z_t), .w(w_t)
);
initial begin
$dumpfile("waveform.vcd");
$dumpvars;
x_t = 0;
y_t = 0;
#10;
if (z_t == 0 && w_t == 0)
$display("0 0 -> 0 0 success");
else
$display("0 0 -> 0 0 fail");
x_t = 0;
y_t = 1;
#10;
if (z_t == 0 && w_t == 1)
$display("0 1 -> 0 1 success");
else
$display("0 1 -> 0 1 fail");
x_t = 1;
y_t = 0;
#10;
if (z_t == 0 && w_t == 1)
$display("1 0 -> 0 1 success");
else
$display("1 0 -> 0 1 fail");
x_t = 1;
y_t = 1;
#10;
if (z_t == 1 && w_t == 1)
$display("1 1 -> 1 1 success");
else
$display("1 1 -> 1 1 fail");
end
endmodule
Le righe da 2 a 8 sono molto vicine a quello che vediamo nel disegno.
Dichiariamo dei reg che useremo per pilotare gli ingressi della rete combinatoria, e dei wire che useremo per monitorarne le uscite.
Dichiariamo poi la nostra rete combinatoria: lo statement a righe 5-8 è nella forma tipo_modulo nome_istanza( [lista porte] );.
Possiamo immaginare questo statement come equivalente dell'atto fisico di prendere un chip di tipo RC, che chiameremo con un nome d'istanza rc per distinguerlo dagli altri, e posizionarlo nella nostra rete collegandone i vari piedini con altri elementi: l'ingresso x al reg x_t, l'uscita z al wire z_t, e così via.
La notazione mostrata a righe 6-7 è con parametri nominati (named parameters), dove si indicano esplicitamente gli assegnamenti tra parametro del componente e componente esterno. Si può sempre utilizzare l'alternativa più nota - perché unica scelta in molti linguaggi, come C - ossia la notazione con parametri posizionali (positional parameters), dove l'associazione è data dalla corrispondenza con l'ordine di dichiarazione dei parametri.
La notazione con parametri posizionali può sembrare meno prolissa, ma è anche più pericolosa. In primo luogo, si basa sul fatto di ricordarsi esattamente l'ordine dei parametri, quando è invece facile distrarsi e scambiarli di posto. In secondo luogo, non permette di saltare una posizione, mentre vedremo esempi dove collegare qualcosa a una o più uscite di una rete è del tutto opzionale.
Queste limitazioni possono sembrare semplici da aggirare, ma il vero problema è che a una semplice svista su un assegnamento di parametri posizionali corrisponde una lunga e faticosa fase di debug in cui tutto sembra comportarsi in modo completamente casuale.
Guardando le righe successive, ci sono diversi concetti che hanno un senso in questo contesto mentre altrove o hanno un senso diverso o sono del tutto privi di senso.
Iniziamo dall'uso di reg come variabili, assegnando valori in serie come in un programma C.
Nelle reti sincronizzate, vedremo che reg viene usato con significato e comportamento completamente diverso.
Vediamo poi che usiamo un blocco initial begin ... end: questo contiene degli statement, eseguiti come un programma uno alla volta, separati talvolta da delle attese esplicite come #10 che attende 10 unità di tempo.
Il termine initial significa che il programma è eseguito "all'inizio della simulazione": questo è un esempio di concetto completamente insensato per dell'hardware, dove non esiste un tempo 0.
Altri statement che hanno senso solo in una simulazione sono $display, che stampa a terminale, e $dumpfile e $dumpvars, che producono invece un file waveform.vcd che possiamo studiare con GTKWave.
Leggendo il codice come un programma, vediamo che questa testbench altro non fa che testare tutti e 4 i possibili stati di x e y, confrontando le uscite z e w con i valori attesi.
Le unità temporali (sia di default che di volta in volta) si possono specificare, ma noi per semplicità non lo facciamo. Come vedremo dalle waveform, di conseguenza ogni valore viene interpretato di default come secondi, cosa decisamente poco realistica, ma comunque di nessun impatto per i nostri usi.
Per eseguire il test useremo tre programmi: iverilog e vvp, dalla suite Icarus Verilog, e GTKWave.
A differenza dell'ambiente per Assembler, questi sono facilmente reperibili per ogni piattaforma, o compilabili dal sorgente.
Qui si trovano installer per Windows.
iverilog è il programma che compila la nostra simulazione. La sintassi è la seguente:
iverilog -o nome_simulazione testbench.v mia_rete.v [altri file .v]
I file per questo test sono scaricabili qui e qui.
Il file prodotto da iverilog non è direttamente eseguibile, ma va eseguito usando vvp:
vvp nome_simulazione
Otteniamo un output come il seguente:
VCD info: dumpfile waveform.vcd opened for output.
0 0 -> 0 0 success
0 1 -> 0 1 fail
1 0 -> 0 1 fail
1 1 -> 1 1 success
La prima riga è relativa ai comandi $dumpfile e $dumpvars, ci informa semplicemente che la simulazione sta effettivamente salvando i dati su waveform.vcd.
Le righe successive sono invece quelle stampate dai nostri $display: vediamo che alcuni test sono falliti.
Alcune versioni di iverilog aggiungono di default una stampa del tipo "$finish called at ..." al termine della simulazione, altre no.
Un test che fallisce indica soltanto che il codice di test e il codice testato sono in disaccordo. La maggior parte delle volte, se fatto bene, il test rappresenta la specifica desiderata, mentre ciò che è testato ne indica solo l'implementazione. Per questo, di solito, ha ragione il test e va cambiato ciò che è testato.
Cerchiamo di capire perché il test fallisce, e quindi in cosa la rete RC non segue la specifica.
Le stampe ci indicano i valori attesi e il fatto che non corrispondono con quelli prodotti da RC, non quali valori sono stati trovati in z e w.
Potremmo cambiare le stampe per includerlo, ma è facile intuire che questo approccio non scala bene: non possiamo stampare a schermo tutte le variabili in tutte le situazioni.
È per questo che si usa la waveform.
Lanciamo GTKWave con il comando
gtkwave waveform.vcd
Si dovrebbe aprire quindi una finestra dalla quale possiamo analizzare l'evoluzione della rete, filo per filo, nel tempo.
Espandiamo le reti nel menu a sinistra, selezioniamo la rete rc e quindi gli input x e y e gli output z e w, clicchiamo poi Append.
Otteniamo una schermata come quella in figura.
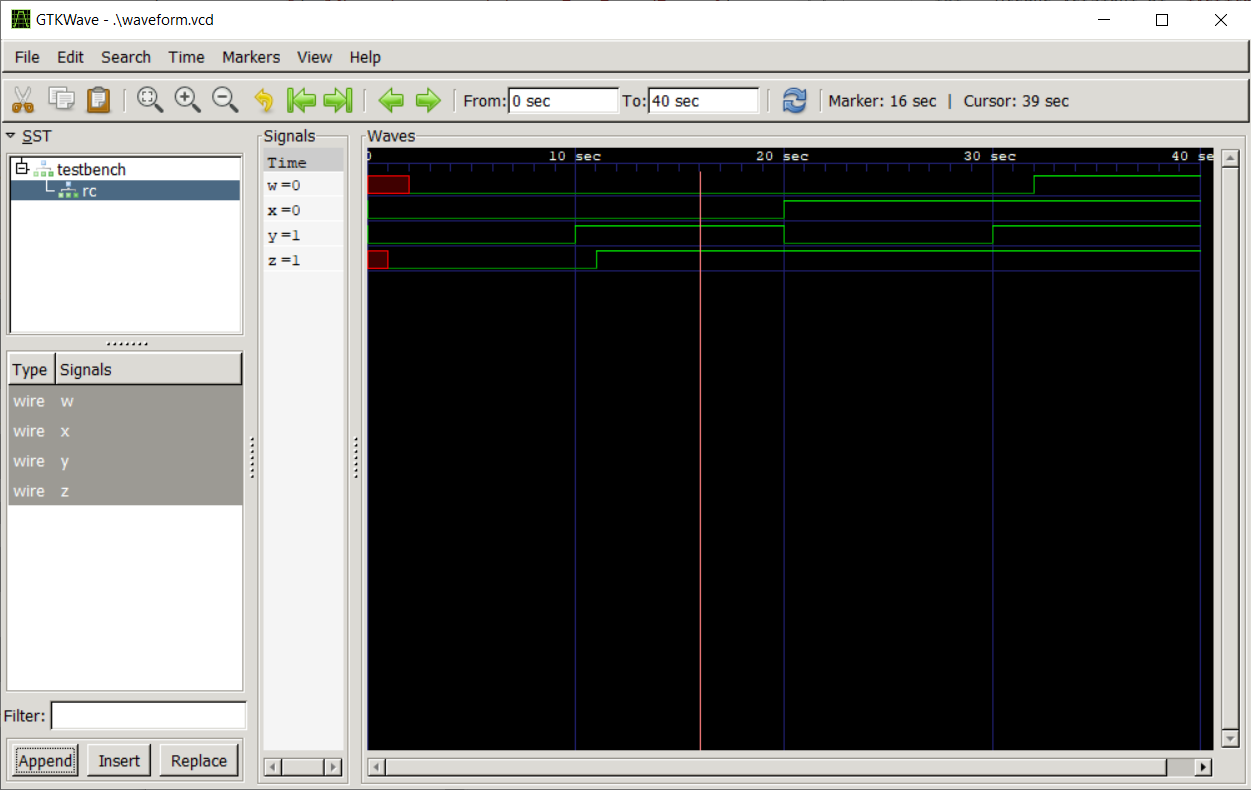
La schermata mostra l'evoluzione nel tempo dei fili selezionati, in particolare nel momento selezionato (la linea verticale rossa).
GTKWave usa linee verdi con valore alto o basso per elementi da un singolo bit che hanno valore logico 0 o 1. In caso di elemento da più bit, utilizza linee verdi sopra e sotto il valore corrente dell'elemento (si può cambiare come sono interpretati i bit usando il menu contestuale).
Le aree di colore rosso indicano punti in cui il valore logico è non specificato, 'bx, tipicamente perché uno o più bit dell'elemento non sono unicamente determinabili.
Una linea in mezzo di colore giallo vuol dire invece alta impedenza, 'bz, che non è un valore logico e vuol dire che, elettricamente, il filo non è connesso.
Sia 'bx che 'bz hanno contesti ed usi utili in cui è normale che compaiano, ma molto spesso sono sintomo di un errore e un buon punto di partenza per il debug.
Vediamo dalla waveform i valori di w e z in corrispondenza dei test falliti: in entrambi i casi il test richiede z a 0 e lo trova a 1, w a 1 e lo trova a 0.
Notiamo quindi che il test si aspetta che z si comporti come un AND e w come un OR, mentre vediamo che succede il contrario.
Dobbiamo quindi scambiare gli assign delle due uscite.
module RC(x, y, z, w);
input x, y;
output z, w;
assign #1 z = x & y;
assign #2 w = x | y;
endmodule
Una volta cambiato il codice, vorremmo ricompilare e rieseguire la simulazione.
Ma il comando gtkwave waveform.vcd blocca il terminale finché non chiudiamo la finestra.
Potremmo chiudere GTKWave e riavvarlo dopo, ma questo significa rifare daccapo tutto il setup per analizzare le waveform.
È per questo una buona idea utilizzare una delle seguenti strategie:
- usare due terminali, uno dedicato a
iverilogevvp, l'altro agtkwave - lanciare il comando in background. Nell'ambiente Windows all'esame, questo si può fare con un
&in fondo:gtkwave waveform.vcd &
In entrambi i casi, otteniamo di poter rieseguire la simulazione mentre GTKWave è aperto. Possiamo quindi sfruttare il pulsante Reload, che caricherà le nuove waveform dall'ultima simulazione senza dover reimpostare l'interfaccia.
& non funzionaIn alcune installazioni di Powershell l'operatore & non funziona.
L'operatore è un semplice alias per Start-Job, e si può ovviare al problema usando questo comando per esteso:
Start-Job { gtkwave waveform.vcd }
L'operatore è documentato qui.
Full adder, descrizione e sintesi di reti combinatorie
In generale, la differenza tra descrizione e sintesi è la seguente: una descrizione si limita a dire cosa una rete fa, senza scendere oltre nei dettagli implementativi; una sintesi mostra invece come si implementa questo comportamento. Una sintesi è un modo di realizzare una rete che si comporta come indicato dalla descrizione, e ci possono essere diversi modi (seguendo diversi modelli, algoritmi, criteri di costo) per sintetizzare una descrizione.
Per il caso delle reti combinatorie, vediamo l'esempio del full adder, partendo dal caso a 1 bit (testbench, descrizione, sintesi).
module full_adder(
x, y, c_in,
s, c_out
);
input x, y;
input c_in;
output s;
output c_out;
assign #5 {c_out, s} = x + y + c_in;
endmodule
Le parentesi graffe, come in {c_out, s}, si può usare per raggruppare elementi sia a destra che a sinistra di un assegnamento.
Bisogna stare però attenti alle dimensioni in bit, e cosa viene assegnato a cosa.
Questa è una descrizione del full adder: ci spiega cosa fa questo modulo, indicando le porte e la relazione tra ingressi e uscite, ma non ci dice nulla su come è implementata questa relazione.
Infatti, la riga 10 utilizza l'operatore + del linguaggio Verilog, non ci spiega come si fa la somma.
Quando si usano espressioni in questo modo, il compilatore Verilog non le traduce in hardware, ma ne calcola direttamente il risultato usando la nostra CPU a tempo di simulazione.
module full_adder(
x, y, c_in,
s, c_out
);
input x, y;
input c_in;
output s;
output c_out;
assign #5 s = x ^ y ^ c_in;
assign #5 c_out = ( x & y ) | ( y & c_in) | ( x & c_in );
endmodule
Questa invece è una sintesi: ci mostra come realizzare il sommatore usando operatori logici elementari.
Un altro modo per definire sintesi è il fatto che siamo in grado, a partire dalla sintesi, di produrre lo schema circuitale corrispondente. Infatti, dal codice sopra possiamo ricavare il seguente schema.
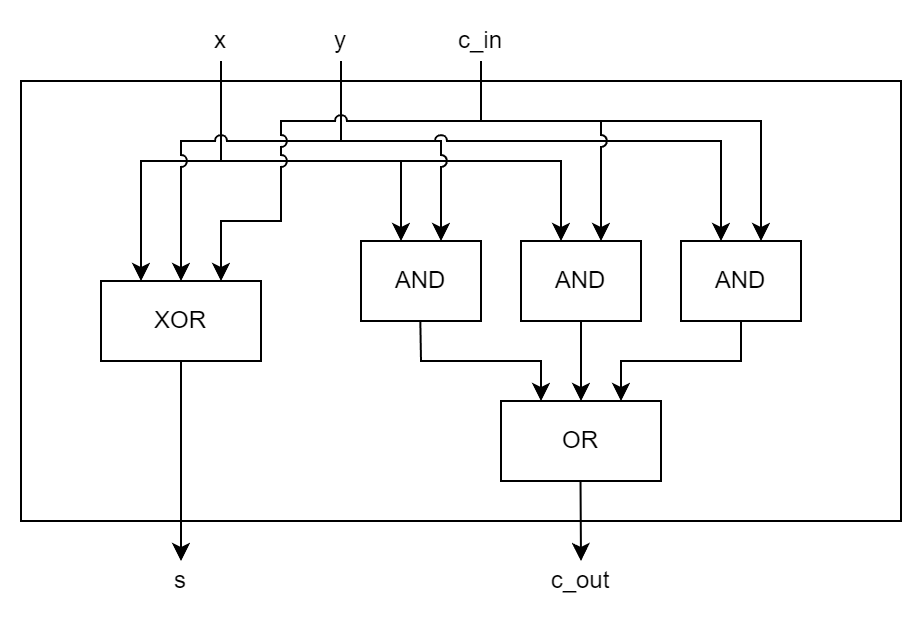
Vediamo ora il caso di un full adder a 3 bit (testbench, descrizione, sintesi).
Per una descrizione, ci basta seguire l'esempio del caso a 1 bit, con l'aggiunta delle diverse dimensioni dei fili.
module full_adder_3(
x, y, c_in,
s, c_out
);
input [2:0] x, y;
input c_in;
output [2:0] s;
output c_out;
assign #5 {c_out, s} = x + y + c_in;
endmodule
La dichiarazione con [2:0] indica che l'elemento è composto da 3 bit, indicizzati da 0 a 2.
Questi indici possono poi essere utilizzati per selezionare uno o più componenti.
Per esempio, con x[2:1] si selezionano i bit 2 e 1 di x, con x[1] solo il bit 1.
Come prima, questa è una descrizione perché non ci dice affatto come realizzare il sommatore, e non possiamo disegnare uno schema circuitale a partire da questo codice senza sapere già, da una altra fonte, come realizzare un full adder a 3 bit.
Passiamo invece alla sintesi. Sappiamo che il full adder è un esempio di rete componibile, nel senso che possiamo realizzare un full adder a N bit usando N full adder a 1 bit. Vediamo come partendo, questa volta, dallo schema circuitale.
![Schema di un full-adder a 3 bit.
Si utilizzano 3 full-adder a 1 bit (FA), ciascuno ha come ingressi i bit corrispondenti degli ingressi 'x' e 'y', e produce il corrispondente bit dell'uscita 's': il primo FA ha in ingresso 'x[0]' e 'y[0]' e produce l'uscita 's[0]', e così via.
Per i riporti, si usa lo schema 'ripple carry': l'ingresso 'c_in' va al primo FA, la cui uscita 'c_out' va in ingresso al secondo FA, e così via fino all'uscita 'c_out' dell'ultimo FA, che corrisponde al 'c_out' dell'intero full-adder a 3 bit.](/reti-logiche-esercitazioni/2025-26/img/verilog/1/full-adder-3.drawio.png)
Da questo schema, si evince che sappiamo realizzare un full adder a 3 bit se sappiamo già realizzare un full adder a 1 bit. Questa relazione si conserva anche nel codice Verilog: nella sintesi di una rete combinatoria si possono utilizzare altre reti combinatorie di cui, a loro volta, si conosce la sintesi.
module full_adder_3(
x, y, c_in,
s, c_out
);
input [2:0] x, y;
input c_in;
output [2:0] s;
output c_out;
wire c_in_1;
full_adder fa_0 (
.x(x[0]), .y(y[0]), .c_in(c_in),
.s(s[0]), .c_out(c_in_1)
);
wire c_in_2;
full_adder fa_1 (
.x(x[1]), .y(y[1]), .c_in(c_in_1),
.s(s[1]), .c_out(c_in_2)
);
full_adder fa_2 (
.x(x[2]), .y(y[2]), .c_in(c_in_2),
.s(s[2]), .c_out(c_out)
);
endmodule
In questo codice riutilizziamo la rete full_adder che abbiamo sintetizzato prima.
Notiamo come per farlo dobbiamo instanziare la rete tre volte, dandogli nomi diversi (fa_0, fa_1, fa_2), e dichiarare dei nuovi wire per collegarli, c_in_1 e c_in_2.
Infine, utilizziamo indici per indicare le componenti di x e y da collegare a ciascun full_adder, così come quale componente di s è collegata a quale uscita.
Di nuovo, possiamo vedere la corrispondenza tra il codice Verilog e lo schema circuitale: questo non è un caso, anzi è fondamentale. Tolto il caso limite delle testbench simulative, ogni cosa che scriviamo in Verilog ha senso solo se ci è chiaro che tipo di hardware corrisponde a ciò che scriviamo e come si può realizzare.
Questo vale anche quando si fa una descrizione.
Per esempio, abbiamo prima visto come si può descrivere un full adder scrivendo {c_out, s} = x + y + c_in.
Questo ci permette di essere meno prolissi, a patto che si sa come si fa un sommatore.
Vedremo più avanti, nelle reti sincronizzate, esempi di cose che sono semplici da scrivere in descrizione, affidandosi al simulatore per eseguirne la logica, ma che si rivelano poi molto difficili da sintetizzare.